

技术是机器学习的子部分之一。
推荐系统是什么时候出现的?
推荐系统是最近才出现的。 1990 年,瑞典科学家 Jussi Karlgren 首次提到该技术,将其描述为“数字书架”。 这项工作为他今后的研究奠定了基础。
在 2000 年代,推荐算法开始进入电子商务领域。 该领域的先驱之一是在线零售商亚马逊。
2006 年,当时订阅 DVD 的公司 Netflix 发起了一场价值 100 万美元的推荐算法竞赛。 2009 年,该奖项授予 BellKor 的 Pragmatic Chaos 团队。
2010 年,推荐系统出现在社交网络上。 今天,大多数流行的平台已经放弃使用按时间顺序排列的提要,转而使用算法提要。
推荐系统是如何工作的?
目前推荐系统中使用的主要方法有两种:协同过滤和基于内容的模型。
协同过滤的主要原理是根据其他具有相似兴趣的用户的数据生成推荐。 过滤是基于用户和基于项目的。
基于用户的算法的主要任务是根据他们消费的产品和他们给出的评分,找到兴趣尽可能相似的用户。 假设 Anna 和 Vadim 买了果汁、面包和酸奶。 众所周知,Maxim 经常购买果汁和面包。 这意味着需要推荐他购买酸奶。
基于项目的建议从相反的角度看待问题:找到相似的对象并查看之前如何评估它们。 让我们来看看Maxim是否喜欢酸奶。 我们知道他喜欢果汁和面包。 酸奶作为一种食品,也有类似的特点。 所以我们可以假设Maxim会喜欢这个产品。
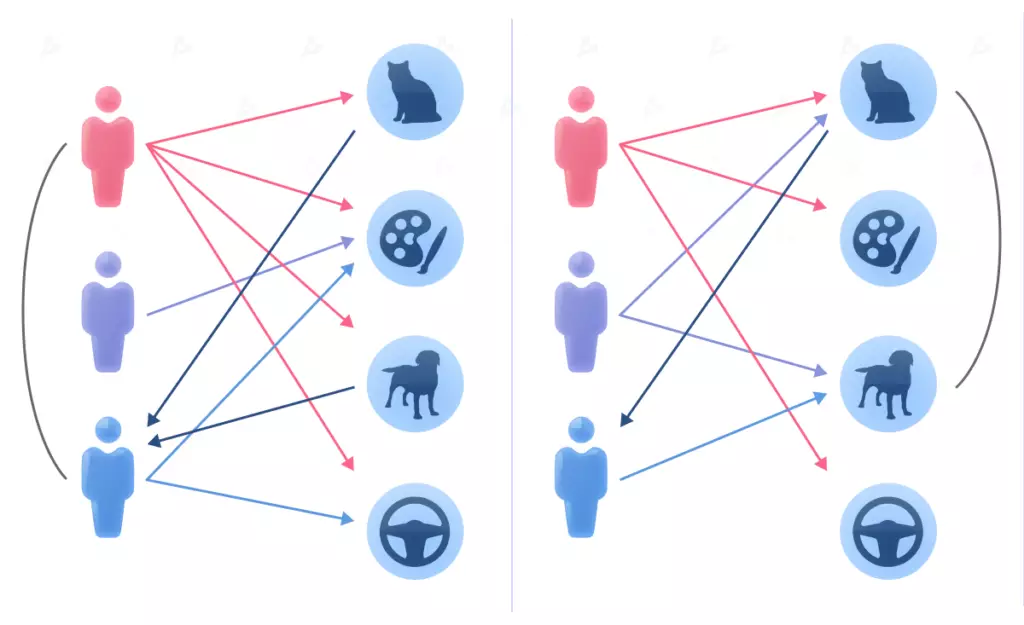 在基于用户(左)和基于项目(右)的过滤中确定用户相似度的逻辑。
在基于用户(左)和基于项目(右)的过滤中确定用户相似度的逻辑。
协同过滤的目的是找到一个用户对某个特定对象进行评分,并计算他对数据库中所有对象的评分向量的相关系数。 为此,经常使用k-最近邻法。
基于内容的模型的中心是一个对象。 算法工作不需要用户评级。 模型了解表征对象的任何属性很重要:作者、流派、原产国、制造商等。同时,有必要了解并非所有这些属性都与消费者相关,所以你应该将自己限制在主要属性上。
最近,基于内容的模型变得非常流行。 他们不需要经过长时间的培训,开发人员可以立即开始为用户推荐产品。
然而,这种方法也有缺点。 很多用户注意到,在谷歌上搜索到某个产品后,他们被广告“追逐”到某个在线商店购买该产品。 为了减少关于此类广告不相关的负面评测的数量,开发人员用基于知识的模型来补充算法。 他们也不依赖评级,而只考虑用户和产品配置文件。
推荐系统如何收集数据?
推荐算法的数据可以通过显式和隐式方式收集。
明确的方法包括要求用户以不同的等级对项目进行评分,从最好到最差对它们进行排名,比较两个相似的产品,或者上架最喜欢的项目。 关键是用户理解他的数据被算法使用并同意他们的处理。
在隐蔽方法中,网站访问者并不总是意识到他们的行为可以被推荐系统使用。 这包括 cookie、Google 或 Facebook 广告跟踪器、视频交互的详细分析等等。
通常,许多政府要求网站在收集此类数据时通知访问者。 但是,用户并不总是可以选择移除。
推荐系统在哪里使用?
如前所述,推荐系统广泛用于电子商务。 在他们的帮助下,在线商店可以就“你可能还喜欢”区块中的相关产品向客户提供建议,或者直接在购物篮中提供补充产品。 此外,如果产品没有股票,算法可以找到类似产品。
邮件列表也经常使用个性化推荐。
亚马逊、Ozon 或 Wildberries 等零售商也使用类似的算法。
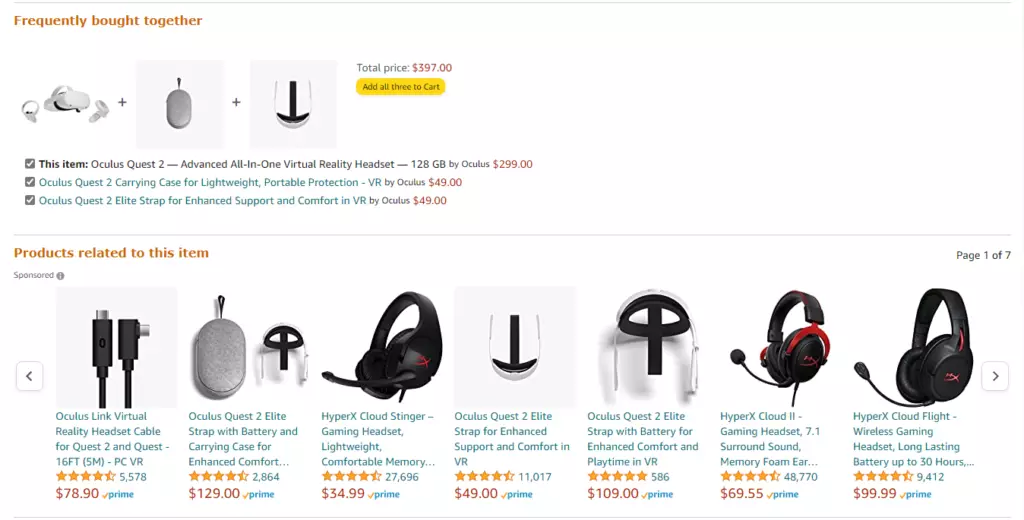 亚马逊产品卡片中的推荐。 数据:亚马逊。
亚马逊产品卡片中的推荐。 数据:亚马逊。
主要的流媒体服务也使用推荐系统。 其中包括 Netflix、Spotify、Apple Music、Yandex.Music、YouTube、Megogo 等。
推荐算法也广泛用于社交网络。 Facebook、Twitter、Instagram、VKontakte 等多年来一直在向用户展示算法收集的内容。 其中只有少数允许你切换到时间线。
推荐系统存在哪些问题?
推荐系统有许多限制。 其中之一是冷启动问题 – 当尚未增持足够数量的数据以使算法工作时。 这对于一个新的或冷门的房产被少数用户欣赏,或者对于一个与普通用户有很大不同的非凡消费者来说,这是一个典型的情况。
在这种情况下,评级会被人为调整。 例如,分数不是作为位置平均值计算的,而是作为平滑平均值计算的。 对于少量评测,对象的评分将趋向于某个“安全平均”,当收集到足够数量的真实评分时,就会关闭人工平均。
推荐算法的另一个问题是偏见。 调整不准确的算法、嵌入其中的刻板印象以及用户操作都会影响信息的排名。
2021 年,Facebook 的广告算法不成比例地向男性和女性展示不同的招聘信息。 在大多数情况下,家庭 Twitter 订阅源的自动照片裁剪工具专注于年轻和苗条的女孩。
在这两种情况下,开发人员都迅速修复了错误,但这并不总是可行的。 谷歌一直面临着对推荐算法工作的批评。
例如,“运动员”和“运动员”的搜索结果非常不同。 对于男性,算法会显示具有运动员专业成就的文章。 然而,对于女性,该系统给出了不同的“吸引力”和“性感”等级。
“运动员”和“运动员”的 Google 搜索结果。 数据:谷歌。
不仅用户,机器人也会影响搜索结果。 2018 年,Reddit 用户在搜索“白痴”时故意操纵谷歌的算法,显示美国前总统唐纳德特朗普的照片。
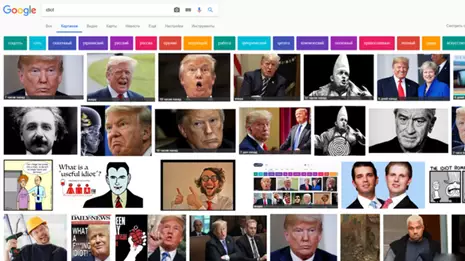 唐纳德特朗普,他被列入白痴的搜索结果。 数据:谷歌。
唐纳德特朗普,他被列入白痴的搜索结果。 数据:谷歌。
在国会就该事件举行的听证会上,该公司的首席执行官 Sundar Pichai 表示,公司员工不会干预信息的排名。 他说,算法通过扫描数百万个搜索字符串并根据 200 多个参数对它们进行排序,从而自行完成。
推荐系统开发人员也可以利用算法偏差。 2021 年 10 月,一名前 Facebook 员工发布了文件,证明该网站上故意使用“有害”工具。 据她说,高层管理人员知道算法对未受保护的人群不宽容。 但该公司并不急于修复这些漏洞,因为此类内容更多地吸引了用户,并通过展示广告增加了公司的收入。
在 Telegram 上订阅 ForkLog 新闻:ForkLog AI – 来自 AI 世界的所有新闻
在文本中发现错误? 选择它并按 CTRL+ENTER
内容搜集自网络,整理者:BTCover,如若侵权请联系站长,会尽快删除。