来自英国实验室 DeepMind 的科学家创造了 XLand 的庞大游戏环境,用于训练多功能 AI 代理。 他们可以执行他们从未遇到过的任务。
强化学习通常在同一游戏中训练和测试代理。 新工作展示了我们的团队如何在巨大的游戏空间中训练有能力的智能体,从而使智能体泛化到保留的测试游戏,并学习实验等行为 https://t.co/fQ9UrOFkMb 1 / pic.twitter.com/UAPX5VgMmO
– DeepMind (@DeepMind) 2021 年 7 月 27 日
研究团队并没有在有限数量的任务上训练代理,而是确定了一系列可以通过程序生成的情况。
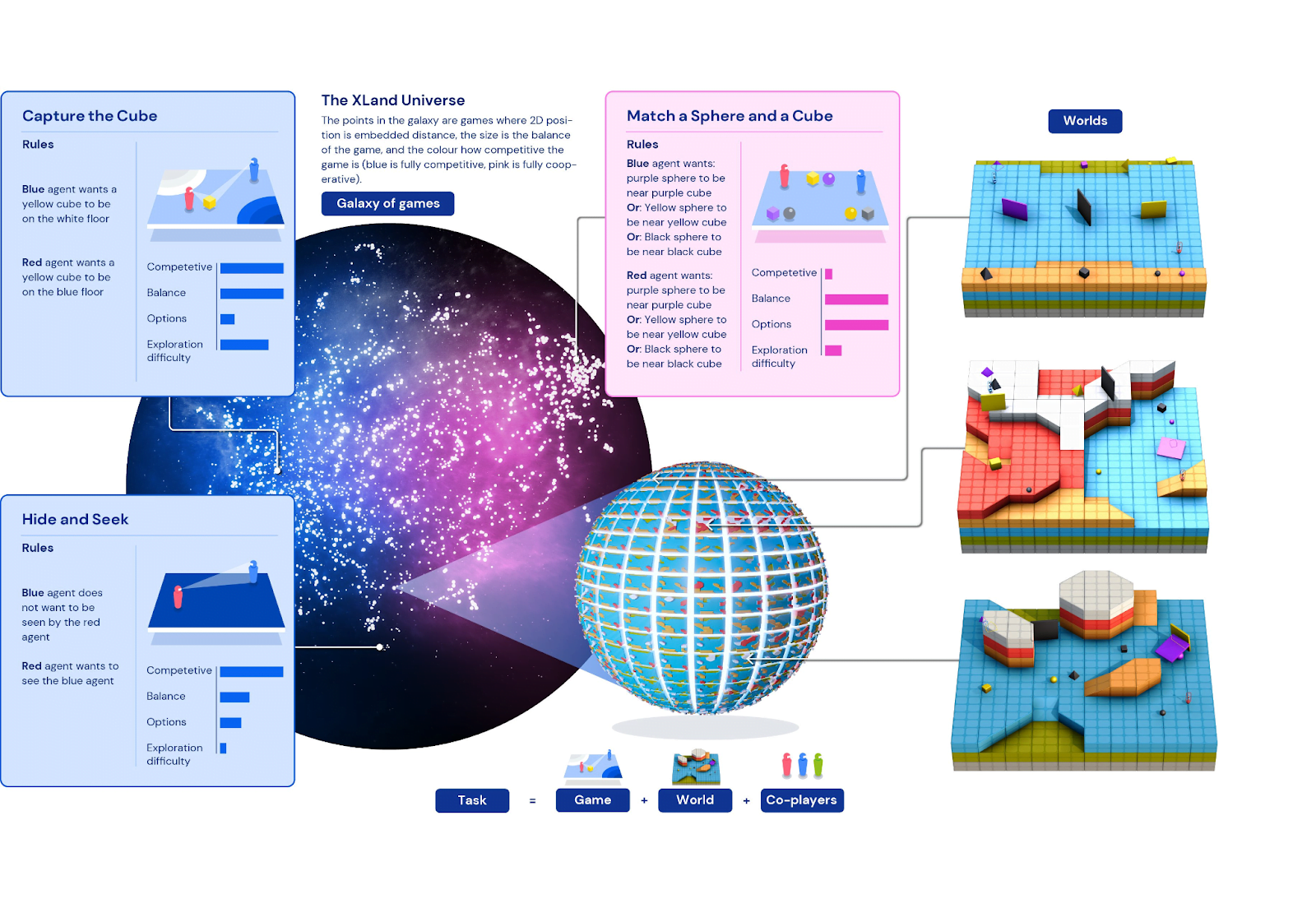
 XLandCosmos的设备。 数据:DeepMind。
XLandCosmos的设备。 数据:DeepMind。
XLand 世界包括许多多人 3D 游戏。 在其范围内,代理在 4,000 个世界中进行了 700,000 次独特的会话。 由于 340 万个独特的任务,最新一代的每个智能体都经历了 2000 亿个学习步骤。
科学家们说,因此,开发人员获得了一种可以成功解决各种问题的算法——从简单的物体搜索到复杂的游戏,例如捉迷藏或夺旗,这些在训练中都没有遇到过。
“目前,我们的智能体可以参与所有程序化创建的评估任务,除了一些人类无法解决的情况,”该研究称。
根据科学家的说法,代理表现出普遍适用于许多任务的普遍启发式行为。
他们补充说:“这种新方法标志着朝着创建可以快速适应不断变化的环境的多功能代理迈出的重要一步。”
回想一下,6 月份,DeepMind 的研究人员表示,强化学习足以实现通用人工智能。
7 月,AI 实验室专家收集并发布了由 AlphaFold 神经网络创建的最完整的人类蛋白质结构数据库。
在 Telegram 上订阅 ForkLog 新闻:ForkLog AI – 来自 AI 世界的所有新闻
发现文中有错误? 选择它并按 CTRL + ENTER
内容搜集自网络,整理者:BTCover,如若侵权请联系站长,会尽快删除。